Making Your Capistrano Recipe Book
If you’ve deployed more than one application with Capistrano, then you’ve probably repeated yourself in most of the deploy scripts. Heck, you’ve probably copied and pasted from one to another just to get things going. Moving your common deployment logic into a gem will prevent this duplication and allow you to codify your best techniques in a single place. It’s building a toolbelt where before the tools were scattered over the garage floor.
Most importantly, removing the onerous job of writing lengthy deploy scripts means you can keep focused on the business value of your application. Basic deployment should never get in the way of that.
I gave a presentation on this topic at the January 2010 Sydney RORO meeting. Below are the slides and in this article I’ll write in more detail about the technique and why it is useful.
Making Your Capistrano Recipe Book
Background
I’ve just finished two years working in an applications development team at the Autralian Medical Council in Canberra. While I was there, we built many tightly-focused Rails apps. Currently there are eight in production and a number more under development. In order to keep things easy to manage, we did a lot of things to simplify the deployment process.
The first step we took was to automate the provision of homogenous virtual servers. I wrote a few thousand lines of bash, tied it to xen-tools, and hey presto, we could build new servers in one command and a couple of minute’s wait. Now that we had a standard server environment for each application, we saw another issue appear: lots of duplication in their Capistrano deploy.rb scripts. So the second measure was to extract all the common Capistrano tasks and configuration into a gem.
Getting Started
Here’s the kind of deploy script you might have for a simple application. First, you’ll have the standard information about your application, its repo, and the target host for deployment.
set :application, 'myapp.mycorp.com'
set :user, 'deployer'
set :deploy_to, "/home/deployer/deployments/#{application}"
set :use_sudo, false
role :app, '192.168.0.1'
role :web, '192.168.0.1'
role :db, '192.168.0.1', :primary => true
set :scm, :git
set :repository, 'git@git.mycorp.net:myapp.git'
set :branch, 'master'
set :deploy_via, :remote_cache
default_run_options[:pty] = true
set :ssh_options, { :forward_agent => true }
Then you’ll want to add some deployment tasks that work with Passenger:
namespace :deploy do
desc "Restarting mod_rails with restart.txt"
task :restart, :roles => :app, :except => { :no_release => true } do
run "touch #{current_path}/tmp/restart.txt"
end
[:start, :stop].each do |t|
desc "#{t} task is a no-op with mod_rails"
task t, :roles => :app do ; end
end
end
Finally, you might have some custom tasks and callbacks to set up your “Thinking Sphinx”:http://freelancing-god.github.com/ts/en/ installation.
before 'deploy:setup', 'sphinx:create_db_dir'
before 'deploy:setup', 'sphinx:generate_yaml'
after 'deploy:update_code', 'sphinx:symlink'
namespace :sphinx do
desc 'Create a directory to store the sphinx indexes'
task :create_db_dir, :roles => :app do
run "mkdir -p #{shared_path}/sphinx"
end
desc 'Generate a config yaml in shared path'
task :generate_yaml, :roles => :app do
sphinx_yaml = <<-EOF
development: &base
morphology: stem_en
config_file: #{shared_path}/config/sphinx.conf
test:
<<: *base
production:
<<: *base
EOF
run "mkdir -p #{shared_path}/config"
put sphinx_yaml, "#{shared_path}/config/sphinx.yml"
end
desc 'Symlink the sphinx yml and config files, and the db directory for storage of indexes'
task :symlink, :roles => :app do
run "ln -nfs #{shared_path}/sphinx #{release_path}/db/sphinx"
run "ln -nfs #{shared_path}/config/sphinx.yml #{release_path}/config/sphinx.yml"
run "ln -nfs #{shared_path}/config/sphinx.conf #{release_path}/config/sphinx.conf"
end
end
Creating a Gem Heirarchy
To extract some of the common patterns from the above deploy script, we’ll need to create a heirarchy of files that we’ll eventually turn into our gem. Here’s how it should look:
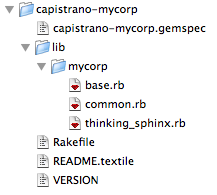
Capistrano Boilerplate
You’ll need something like the following wrapped around any Capistrano code that you use in your gem.
unless Capistrano::Configuration.respond_to?(:instance)
abort "capistrano/ext/multistage requires Capistrano 2"
end
Capistrano::Configuration.instance.load do
# stuff here...
end
The above will only work on Capistrano version 2 or greater (which should be no problem, now that we’re up to 2.5.13).
You could also do the following if you wanted something that works in all versions, including those before 2:
configuration = Capistrano::Configuration.respond_to?(:instance) ?
Capistrano::Configuration.instance(:must_exist) :
Capistrano.configuration(:must_exist)
configuration.load do
# stuff here...
end
Extracting Deployment Code into your Gem
OK, so here’s some of the basic deploy script stuff moved into the lib/mycorp/base.rb file in the gem:
require 'capistrano/mycorp/common'
configuration = Capistrano::Configuration.respond_to?(:instance) ?
Capistrano::Configuration.instance(:must_exist) :
Capistrano.configuration(:must_exist)
configuration.load do
# User details
_cset :user, 'deployer'
_cset(:group) { user }
# Application details
_cset(:app_name) { abort "Please specify the short name of your application, set :app_name, 'foo'" }
set(:application) { "#{app_name}.mycorp.com" }
_cset(:runner) { user }
_cset :use_sudo, false
# SCM settings
_cset(:appdir) { "/home/#{user}/deployments/#{application}" }
_cset :scm, 'git'
set(:repository) { "git@git.mycorp.net:#{app_name}.git" }
_cset :branch, 'master'
_cset :deploy_via, 'remote_cache'
set(:deploy_to) { appdir }
# Git settings for Capistrano
default_run_options[:pty] = true # needed for git password prompts
ssh_options[:forward_agent] = true # use the keys for the person running the cap command to check out the app
end
These lines are lifted directly from the original deploy.rb, with one notable exception: many of the original @set@ calls have been replaced with _cset. _cset is a method used by the Capistrano’s internal deploy.rb file, which we have put inside common.rb:
def _cset(name, *args, &block)
unless exists?(name)
set(name, *args, &block)
end
end
What _cset allows you to do is provide overrideable defaults for any Capistrano option. This is a powerful thing because it allows us to set conventions in our gem. As any Rails developer would know, conventions save time and make it easier for multiple people to work with the same tools or on the same code.
For example, take the user option from above. We’ve set it to ‘deployer’ by default. Because we’ve done it using _cset, any deploy script using this gem can choose to either accept this default or provide its own custom user details.
Note that whenever _cset (or set, for that matter) is called with the a block, it is lazily evaluated. This is important to do if you are including another value provided by a set or _cset call (like :app_dir above that uses the application setting).
Finally, take note of the @abort@ call in the block for setting app_name. You can use abort in your gem whenever there are settings that must be defined by the individual deploy scripts.
Tasks & Callbacks
The Thinking Sphinx tasks and callbacks can go straight into the gem without any modification:
configuration = Capistrano::Configuration.respond_to?(:instance) ?
Capistrano::Configuration.instance(:must_exist) :
Capistrano.configuration(:must_exist)
configuration.load do
_cset(:app_name) { abort "Please specify the short name of your application, set :app_name, 'foo'" }
before 'deploy:setup', 'sphinx:create_db_dir'
before 'deploy:setup', 'sphinx:generate_yaml'
after 'deploy:update_code', 'sphinx:symlink'
namespace :sphinx do
desc 'Create a directory to store the sphinx indexes'
task :create_db_dir, :roles => :app do
run "mkdir -p #{shared_path}/sphinx"
end
desc 'Generate a config yaml in shared path'
task :generate_yaml, :roles => :app do
sphinx_yaml = <<-EOF
development: &main_settings
config_file: #{shared_path}/config/sphinx.conf
pid_file: #{shared_path}/pids/sphinx.pid
production:
<<: *main_settings
EOF
put sphinx_yaml, "#{shared_path}/config/sphinx.yml"
end
desc 'Symlink the sphinx yml and config files, and the db directory for storage of indexes'
task :symlink, :roles => :app do
run "ln -nfs #{shared_path}/sphinx #{release_path}/db/sphinx"
run "ln -nfs #{shared_path}/config/sphinx.yml #{release_path}/config/sphinx.yml"
run "ln -nfs #{shared_path}/config/sphinx.conf #{release_path}/config/sphinx.conf"
end
end
end
In this example, I’ve included the callbacks as well as the tasks. Any deploy script that requires this file from the gem will have these sphinx tasks run automatically. This is useful to keep your deploy scripts concise and your deployment behaviour consistent, but it may not suit everyone. The alternative, to include only the tasks in the gem and require the callbacks to be in the deploy script, would make more sense if you’re planning to offer your gem to a wide audience with varying deployment requirements.
Building the Gem
Building the gem is easy with Jeweler. First, create a Rakefile with something like the following:
begin
require 'jeweler'
Jeweler::Tasks.new do |gemspec|
gemspec.name = "capistrano-mycorp"
gemspec.summary = "MyCorp recipes for Capistrano"
gemspec.description = "MyCorp recipes for Capistrano"
gemspec.email = "tim@openmonkey.com"
gemspec.homepage = "http://github.com/timriley/capistrano-mycorp"
gemspec.authors = ["Tim Riley"]
end
rescue LoadError
puts "Jeweler not available. Install it with: gem install jeweler"
end
Then generate a version number:
echo "0.0.1" > VERSION
And now you can run rake gemspec and rake build to generate a .gem file that you can install on your system. Jeweler also provides easy ways to get your gem onto Gemcutter or Rubyforge, so take a look at its README for more information.
The Result
Now that your gem is installed, you can take to your deploy script with a machete:
set :app_name, 'myapp'
role :app, '192.168.0.1'
role :web, '192.168.0.1'
role :db, '192.168.0.1', :primary => true
require 'capistrano/mycorp/base'
require 'capistrano/mycorp/thinking_sphinx'
That’s it! The result is a beautifully concise script that contains just the information that is pertinent to the application. It is easy to write and easy to read.
Suggested Uses
Building a gem of Capistrano recipes would be useful for:
- Internal teams wanting to standardise their deployment process and remove duplicate code from multiple deploy scripts.
- Agencies or freelancers wanting to reduce the amount of overhead required to start new projects.
- Individuals wanting to share their Capistrano tricks with the community.
- Hosting companies wanting to give their users a set of tasks for easily deploying to their servers.
Find Out More
You can see all my example code in the timriley/capistrano-mycorp repository on GitHub.
I hope this comes in handy!